
For the past couple of years, if you asked an AI expert how to make chatbots smarter, the answer was almost always the same: use Retrieval-Augmented Generation, better known as RAG. It quickly became one of the biggest breakthroughs in modern AI because it solved a problem that every Large Language Model struggled with—limited knowledge and inaccurate answers. Instead of relying only on what it had learned during training, RAG AI allowed models to retrieve relevant information from documents, databases, or company files before generating a response. This approach dramatically improved accuracy and made AI Data Analysis, enterprise search, customer support, and knowledge management far more reliable.
But in 2026, the conversation has started to shift.
Google’s Gemini AI introduced a massive 2 Million Token Context window, allowing the model to process enormous amounts of information in a single prompt. Imagine uploading hundreds of pages of legal contracts, several research papers, thousands of lines of code, financial reports, meeting transcripts, or even an entire book—all at once—and asking questions without first building a retrieval system. Suddenly, a question that seemed impossible just a year ago became surprisingly realistic.
This has sparked one of the hottest debates in artificial intelligence today.
Is Retrieval-Augmented Generation becoming obsolete? Has Google Gemini made traditional RAG unnecessary? Are long-context models the future of enterprise AI, or is this simply another technology trend being blown out of proportion?
The answer isn’t as straightforward as many headlines suggest.
Some AI enthusiasts have boldly declared “RAG is dead,” while researchers and engineers argue that retrieval systems are still essential for handling constantly changing information, reducing costs, and managing enterprise-scale knowledge bases. Somewhere between these two opinions lies the reality—and it’s far more interesting than either extreme.
In this article, we’ll break down What is RAG, why it became the gold standard for enterprise AI, how Gemini’s enormous context window changes the game, and whether long-context models are truly capable of replacing retrieval-based systems. Along the way, we’ll also explore where businesses, developers, researchers, and everyday users stand to benefit as AI enters its next major phase.
If you’ve been hearing terms like “long-context AI,” “2 million tokens,” or “the death of RAG” but aren’t quite sure what they mean, don’t worry. By the end of this guide, you’ll not only understand the technology but also why this debate could shape the future of artificial intelligence for years to come.
What Is Retrieval-Augmented Generation (RAG), and Why Did It Become So Important?
Imagine walking into one of the world’s largest libraries.
You don’t know where any book is located, but standing beside you is a librarian who has spent years organising every shelf. Instead of searching through millions of books yourself, you simply ask a question, and within moments the librarian brings you the most relevant books. You read those pages, understand the information, and then write your answer.
That’s essentially how Retrieval-Augmented Generation works.
Rather than expecting an AI model to remember every piece of information it has ever seen, RAG AI allows it to “look things up” before answering. Instead of relying solely on its internal training, the model retrieves relevant documents from a knowledge source and then generates an answer using that fresh information.
This may sound like a small improvement, but it solved one of the biggest weaknesses of early Large Language Models.
Traditional AI models were trained on vast amounts of internet data, books, articles, and public information. However, once training finished, their knowledge became frozen in time. They couldn’t automatically learn about new events, updated company policies, newly published research, or private business documents unless they were retrained—a process that can take months and cost millions of dollars.
That’s where RAG completely changed the game.
Instead of retraining the model every time new information became available, organisations could simply connect the AI to a searchable knowledge base. Whenever a user asked a question, the system would first retrieve the most relevant documents and then generate an answer based on that information.
Think of it like the difference between taking an exam from memory and being allowed to use an open-book reference. Even if you don’t remember every detail, having access to the right information dramatically improves the quality of your answers.
This simple idea transformed the way businesses used AI.
A hospital could allow an AI assistant to search updated medical guidelines before answering doctors’ questions. A law firm could connect AI to thousands of legal contracts. Banks could retrieve internal compliance documents, while customer support teams could instantly access product manuals and troubleshooting guides.
Instead of giving generic responses, AI suddenly became capable of delivering answers grounded in the latest available information.
That single innovation is why Retrieval-Augmented Generation became one of the most influential developments in modern artificial intelligence.
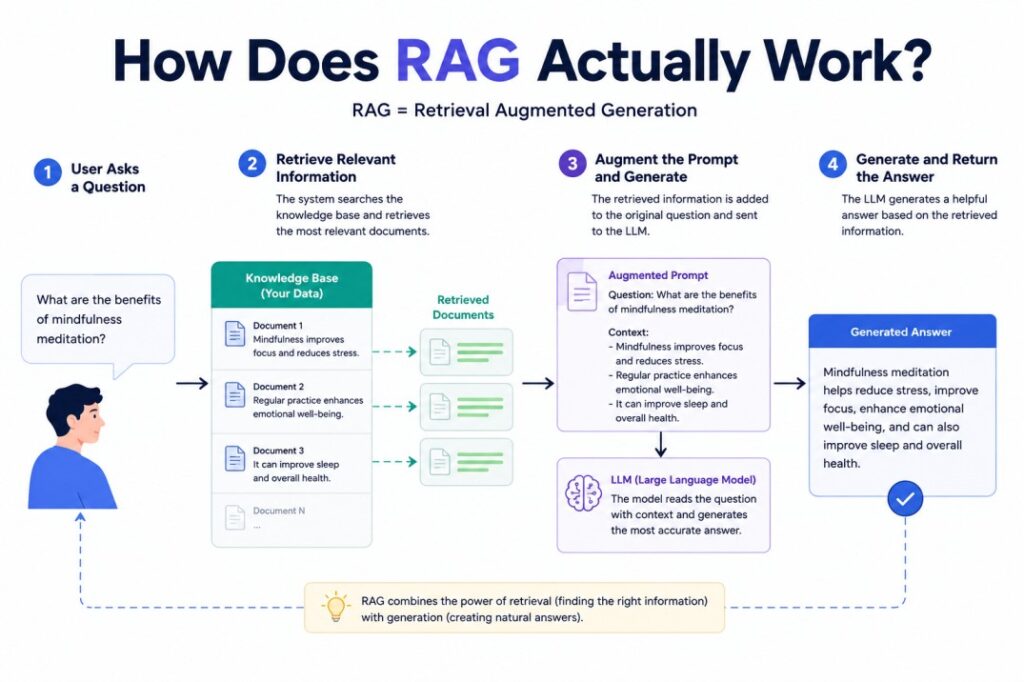
How Does RAG Actually Work?
Although the technology behind RAG sounds advanced, the overall process is surprisingly easy to understand when broken into simple steps.
Let’s imagine a company has over 50,000 internal documents, including HR policies, employee handbooks, sales reports, contracts, meeting notes, technical manuals, and product documentation.
Now suppose an employee asks:
“What is our updated travel reimbursement policy for international conferences?”
Without Retrieval-Augmented Generation, the AI might rely only on whatever similar information it encountered during training. If the company’s policy changed last month, the model would have no way of knowing.
With RAG AI, however, the process looks something like this:
First, the employee asks the question.
The system converts that question into a mathematical representation called an embedding, making it easier to compare meaning rather than just matching keywords.
Next, the AI searches a specialised database containing thousands of indexed company documents. Instead of reading every file, it quickly identifies the documents most closely related to travel reimbursements and international conferences.
Those relevant sections are then passed into the language model alongside the user’s question.
Finally, the AI generates an answer using both its reasoning ability and the newly retrieved company documents.
From the user’s perspective, it all feels seamless. They ask a question and receive a detailed response that reflects the latest company policies rather than outdated information.
This retrieval-first approach is exactly what made AI Data Analysis and enterprise AI so much more reliable. Instead of forcing AI to remember everything, RAG teaches it something arguably more valuable: how to find the right information before answering.
Another advantage is transparency. Many RAG systems can cite the exact document or section used to generate an answer, allowing users to verify the information themselves. This is especially important in industries such as healthcare, finance, legal services, and scientific research, where accuracy matters far more than speed.
For several years, this approach was widely regarded as the smartest way to build trustworthy AI applications.
Then Google introduced something that made the industry pause and ask a difficult question:
“What if the AI didn’t need to retrieve information at all?”
That question brings us to one of the biggest technological leaps in recent years—the arrival of Gemini AI and its astonishing 2 Million Token Context window.
What Is Gemini’s 2 Million Token Context Window, and Why Is It Such a Big Deal?
When Google unveiled Gemini AI with a 2 Million Token Context, it wasn’t just another product update—it sparked one of the biggest discussions in the AI industry. Developers, researchers, and business leaders immediately began asking whether this breakthrough could fundamentally change how Large Language Models work and, more importantly, whether it could reduce the need for Retrieval-Augmented Generation in many real-world applications.
To understand why this announcement matters, we first need to understand what a “token” actually is. Although the term is widely used in artificial intelligence, it often confuses people because it doesn’t directly correspond to words or characters.
Understanding Tokens: The Building Blocks of AI
A token is the smallest unit of text that an AI model processes. Depending on the language and the complexity of the sentence, a single word may consist of one token or several tokens. Even punctuation marks and spaces can influence how text is divided into tokens, which is why token counts are usually higher than word counts.
Think of tokens as pieces of a jigsaw puzzle. Before an AI can understand an article, a contract, or a conversation, it first breaks everything into these smaller pieces. The model then analyses how these tokens relate to one another to understand meaning, context, and relationships between ideas.
The total number of tokens an AI model can process at one time is known as its context window. You can think of this as the model’s short-term working memory. Everything that fits inside this window can be analysed together, allowing the AI to connect ideas across different sections of text and generate more coherent responses.

What Does a 2 Million Token Context Actually Mean?
Numbers like “2 million tokens” sound impressive, but they become much easier to appreciate when translated into everyday examples. A 2 Million Token Context is large enough to hold roughly over a million words, which is equivalent to hundreds of research papers, thousands of pages of legal documents, multiple books, or an extensive software codebase.
Imagine uploading your company’s employee handbook, five years of financial reports, product documentation, customer support tickets, meeting transcripts, and marketing strategies into a single conversation. Instead of analysing each document separately, Google Gemini can potentially examine them together and identify patterns, inconsistencies, and insights across the entire collection.
This represents a significant leap from earlier AI systems, which often had to split large documents into smaller chunks because their context windows were much more limited. Fragmenting information sometimes caused important connections between documents to be lost, making analysis slower and less accurate.
For industries that deal with enormous amounts of information every day, this larger context window opens up entirely new possibilities.
How Previous AI Models Handled Large Documents
Before long-context models became practical, analysing large datasets was rarely straightforward. Most Large Language Models could only process a limited number of tokens in one interaction. If a document exceeded that limit, it had to be divided into smaller sections, analysed separately, and then stitched back together.
This approach worked reasonably well for summarising individual documents but struggled whenever answers depended on understanding relationships across multiple files. Important details could easily be missed if they appeared in different chunks that were never analysed together.
To solve this limitation, organisations adopted Retrieval-Augmented Generation, allowing AI to retrieve only the most relevant sections instead of processing every document from beginning to end. For several years, this became the preferred architecture for enterprise AI systems because it balanced performance, accuracy, and computational cost.
Gemini’s larger context window now challenges that assumption.
Why Gemini’s Long Context Is Changing Data Analysis
The biggest impact of Gemini AI may not be content creation or chatbots—it may be AI Data Analysis. Businesses rarely work with isolated documents. Instead, valuable information is spread across spreadsheets, presentations, contracts, emails, PDFs, meeting recordings, databases, and technical documentation.
Traditional analysis often requires employees to manually compare information from dozens of different sources before reaching a conclusion. Even RAG systems retrieve only the documents they consider most relevant, which means some useful context may never reach the language model.
With a 2 Million Token Context, Gemini can analyse much larger collections of information within a single interaction. This allows the model to identify relationships that span hundreds of pages instead of relying only on a handful of retrieved documents.
For example, a financial analyst could upload several years of annual reports, investor presentations, quarterly earnings, and market research documents together. Rather than summarising each report individually, Gemini could identify long-term trends, compare management strategies over time, highlight recurring financial risks, and explain how market conditions influenced business performance.
Researchers benefit in a similar way. Instead of reading dozens of scientific papers one after another, they can ask Gemini to compare methodologies, identify conflicting conclusions, detect research gaps, and summarise the strongest evidence across the entire collection.
These capabilities move AI beyond simple question-answering and into the realm of genuine analytical reasoning.
Industries That Could Benefit the Most
The ability to process extremely large amounts of information isn’t useful only for technology companies. Almost every knowledge-driven industry stands to gain from long-context AI models.
Some of the sectors expected to benefit the most include:
- Healthcare: Analyse medical research papers, patient histories, treatment guidelines, and clinical trial data together.
- Legal Services: Review thousands of contracts, court judgments, and compliance documents while identifying inconsistencies and potential risks.
- Finance: Compare annual reports, audit documents, investment research, and regulatory filings to uncover long-term business trends.
- Software Development: Understand complete code repositories, documentation, bug reports, and development roadmaps within one conversation.
- Education: Analyse textbooks, lecture notes, research journals, and assignments simultaneously to create comprehensive learning material.
Instead of switching between dozens of files, professionals can interact with a single AI assistant that understands the broader context of their work.

Why Some Experts Believe This Could Reduce the Need for RAG
It’s easy to understand why headlines claiming “RAG is dead” started appearing shortly after Gemini’s announcement. If an AI model can already process hundreds of documents in one prompt, some people naturally wonder why a retrieval system is needed at all.
On the surface, the argument seems convincing. Instead of building a complex pipeline involving embeddings, vector databases, document chunking, and retrieval algorithms, why not simply place everything inside Gemini’s enormous context window and let the model reason over the entire dataset?
For smaller document collections, this approach can work remarkably well. Organisations may find that certain use cases no longer require sophisticated retrieval pipelines because the model can comfortably analyse all the necessary information at once.
However, this doesn’t automatically mean Retrieval-Augmented Generation has become obsolete.
In fact, many AI researchers believe the opposite. They see long-context models and RAG as complementary technologies rather than competing ones. While Gemini solves one important problem by expanding memory, RAG continues solving another equally important challenge—efficiently finding the right information inside constantly growing knowledge bases.
And that’s where the debate becomes truly interesting.
Is RAG Really Dead? Looking Beyond the Headlines
Ever since Google showcased Gemini AI with its impressive 2 Million Token Context, social media has been flooded with bold claims. Headlines like “The Death of RAG,” “Vector Databases Are Finished,” and “Long Context Models Have Replaced Retrieval Systems” quickly gained attention. While these statements make for eye-catching posts, they oversimplify a much more nuanced reality.
The truth is that technology rarely replaces another technology overnight. Instead, new innovations usually change where and how existing tools are used. Cloud computing didn’t eliminate on-premise servers completely, streaming services didn’t end television, and smartphones didn’t replace laptops. They simply changed their role. The same principle applies to Retrieval-Augmented Generation.
Long-context models solve one important challenge by allowing AI to process significantly larger amounts of information in a single interaction. However, RAG was never created just because AI models had small context windows. It was developed to solve several different problems at the same time, many of which still exist today.
Before deciding whether Retrieval-Augmented Generation is becoming obsolete, it’s worth understanding exactly why businesses invested so heavily in it in the first place.
Why Businesses Adopted RAG Instead of Relying Only on AI Models
When organisations first started integrating Large Language Models into their workflows, they quickly encountered a practical limitation. Their most valuable information wasn’t publicly available on the internet. Instead, it lived inside private documents, internal databases, customer records, research papers, contracts, spreadsheets, and company policies that changed regularly.
Training a new AI model every time a document was updated wasn’t realistic. It required significant computational resources, time, and expense. Businesses needed a solution that could provide fresh information without rebuilding the entire model.
This is where Retrieval-Augmented Generation became so valuable. Instead of storing every piece of knowledge inside the model itself, RAG connected AI to external knowledge sources. Whenever a user asked a question, the system searched for the most relevant documents, retrieved them, and allowed the language model to generate an informed response using that latest information.
This architecture transformed enterprise AI because it separated knowledge from reasoning. The knowledge remained inside searchable databases, while the AI focused on understanding and explaining that information rather than memorising everything.
That distinction remains important even in the era of long-context models.
Where RAG Still Has a Clear Advantage
Although Google Gemini can analyse enormous amounts of information, there are several situations where Retrieval-Augmented Generation continues to outperform simply loading everything into a prompt. These advantages explain why many enterprise AI systems are expected to keep using RAG for years to come.
1. Continuously Changing Information
One of RAG’s greatest strengths is its ability to work with information that changes every day. News articles, stock prices, customer support tickets, medical research, product inventories, legal regulations, and company policies are constantly being updated. A retrieval system always searches the latest available documents before generating a response, ensuring that the AI works with current information rather than relying on older context.
Long-context models, on the other hand, only know what has been included in the prompt. If yesterday’s policy has already been replaced, someone must manually provide the updated document again. RAG automates this process, making it particularly useful for organisations that deal with rapidly changing information.
2. Lower Operational Costs
Processing millions of tokens is an impressive technical achievement, but it also requires significantly more computational power. Loading hundreds of documents into every interaction may not always be practical, especially when a user’s question only requires information from two or three documents.
A well-designed Retrieval-Augmented Generation system retrieves only the relevant content needed for a particular question. This targeted approach reduces unnecessary processing, lowers infrastructure costs, and improves response efficiency. For organisations handling thousands or even millions of AI requests each day, these savings can be substantial.
3. Better Scalability for Enterprise Knowledge
Consider a multinational organisation that generates thousands of new documents every single day. Internal emails, compliance reports, contracts, invoices, project documents, customer interactions, and software updates continuously expand the company’s knowledge base.
Even with a 2 Million Token Context, loading an entire corporate knowledge repository into every prompt would be impractical. RAG scales much more effectively because it searches only the information relevant to each individual request. As enterprise knowledge grows into millions or even billions of documents, retrieval systems remain an efficient way to manage that complexity.
4. Improved Source Verification
Many industries require complete transparency regarding where information originates. Legal professionals need references to contracts, doctors require citations from clinical guidelines, financial analysts must verify regulatory documents, and researchers depend on reliable academic sources.
Modern RAG AI systems often provide links or citations showing exactly which documents were used to generate an answer. This makes responses easier to verify and increases user confidence, particularly in industries where factual accuracy is essential.
Where Gemini’s Long Context Clearly Outperforms Traditional RAG
While RAG continues to offer significant advantages, there are also situations where Gemini AI delivers capabilities that traditional retrieval systems struggle to match. These scenarios usually involve complex reasoning across large collections of interconnected information rather than simply locating the correct document.
One major advantage is cross-document analysis. Instead of retrieving five relevant documents and answering a question, Gemini can simultaneously analyse hundreds of related files and identify relationships between them. This broader perspective allows the model to detect patterns, contradictions, trends, and hidden insights that might never appear when documents are processed individually.
For example, imagine analysing five years of customer feedback alongside product release notes, marketing campaigns, and technical support records. Rather than answering isolated questions, Google Gemini can explain how product improvements influenced customer satisfaction over time and identify recurring issues that continued across multiple releases.
Another area where long-context models excel is software engineering. Developers often work with extensive codebases containing source code, documentation, architecture diagrams, bug reports, and technical specifications. Instead of retrieving small code snippets, Gemini can maintain awareness of the broader software architecture, making it easier to understand dependencies and recommend structural improvements.
Researchers also benefit significantly from long-context reasoning. Rather than comparing individual scientific papers, they can ask the model to analyse entire collections of studies, identify conflicting findings, summarise evidence across disciplines, and highlight areas where further investigation is needed.
These examples illustrate why long-context AI represents much more than simply having a larger memory. It enables a deeper level of reasoning across information that was previously too fragmented for AI systems to analyse effectively.

RAG vs Gemini’s Long Context: Which One Is Better?
The debate often presents the question as though there must be a single winner. In reality, both technologies solve different challenges, and the better choice depends entirely on the use case.
| Feature | Retrieval-Augmented Generation (RAG) | Gemini’s Long Context |
| Information Source | Retrieves relevant external documents | Processes large amounts of uploaded information directly |
| Best For | Frequently changing knowledge bases | Large-scale document reasoning |
| Cost Efficiency | Generally lower for repetitive enterprise queries | Can be higher for very large prompts |
| Data Freshness | Always retrieves the latest information | Depends on the documents provided in the prompt |
| Cross-Document Reasoning | Limited by retrieved content | Excellent for analysing relationships across hundreds of documents |
| Enterprise Scale | Highly scalable with growing databases | Best suited when large document collections fit within the available context |
| Transparency | Often includes document citations | Depends on implementation |
Looking at the comparison, it becomes clear that the question isn’t whether one technology replaces the other. Instead, organisations should ask which architecture best fits their specific workflow.
The Rise of Hybrid AI Systems
Interestingly, many AI researchers believe the future doesn’t belong exclusively to Retrieval-Augmented Generation or long-context models. Instead, it belongs to systems that intelligently combine both approaches.
Imagine an enterprise AI assistant receiving a complex business question. Instead of blindly retrieving documents or loading everything into memory, the system first searches its knowledge base to identify the most relevant information. It then uses Gemini AI’s large context window to analyse those documents together, compare related information, and generate a detailed response with supporting evidence.
This hybrid architecture combines the strengths of both technologies. Retrieval ensures that information remains current and scalable, while long-context reasoning allows the model to analyse much larger collections of relevant documents without losing important relationships.
Many experts believe this approach represents the next evolution of Enterprise AI rather than the complete replacement of RAG. As context windows continue to expand and retrieval systems become more intelligent, businesses are likely to benefit from architectures that combine both capabilities instead of choosing only one.
The discussion, therefore, shouldn’t be about the “death” of RAG. It should be about how AI architectures are evolving to become more flexible, more intelligent, and better suited to solving increasingly complex real-world problems.
The Future of AI: Beyond RAG and Long-Context Models
If there’s one lesson the AI industry has taught us over the past few years, it’s that today’s breakthrough quickly becomes tomorrow’s foundation. Just a few years ago, simply generating human-like text felt revolutionary. Then came Retrieval-Augmented Generation, which significantly improved accuracy by allowing AI to access external knowledge. Now, Google Gemini has pushed the conversation further with its 2 Million Token Context, showing that AI can analyse far larger amounts of information than previously imagined.
But this isn’t the final destination.
The next generation of Artificial Intelligence is expected to combine larger context windows, smarter retrieval systems, improved reasoning, persistent memory, and autonomous AI agents into a single ecosystem. Instead of asking whether one technology will replace another, the industry is increasingly focused on how these technologies can work together to create more capable and trustworthy AI systems.
Future AI assistants may not simply answer questions. They could monitor projects, analyse business performance in real time, compare historical trends, prepare presentations, write reports, identify risks, and even recommend decisions while continuously learning from updated information sources. In that future, context windows, retrieval systems, reasoning models, and memory mechanisms will each play an important role rather than competing against one another.
What This Means for Businesses Investing in AI
For businesses planning their AI strategy, the debate around Retrieval-Augmented Generation versus long-context models shouldn’t be viewed as a choice between old and new technology. Instead, it should be seen as an opportunity to redesign AI workflows based on the type of information they manage and the problems they need to solve.
Organisations with relatively small but information-rich document collections may benefit greatly from long-context models. A consulting firm analysing project reports, a legal practice reviewing contracts for a specific case, or a research organisation comparing hundreds of scientific papers could simplify their workflows by allowing Gemini AI to process large document collections directly. In these situations, reducing architectural complexity can improve both productivity and user experience.
On the other hand, enterprises managing continuously expanding knowledge bases are likely to continue relying on Retrieval-Augmented Generation. Banks, hospitals, government departments, insurance providers, and multinational corporations generate new documents every hour. Searching these dynamic repositories efficiently remains one of RAG’s greatest strengths, especially when responses must always reflect the most recent information available.
Another important consideration is governance. Many organisations operate under strict regulatory requirements that demand transparency, audit trails, and clear documentation of how AI-generated answers are produced. Retrieval systems naturally support these requirements by referencing the original source documents used during response generation. Long-context models can also support transparency, but retrieval-based architectures often make compliance easier to manage at enterprise scale.
What Developers Should Learn from This Shift
For software developers and AI engineers, one of the biggest takeaways is that system design is becoming more flexible than ever before. Building AI applications is no longer just about selecting the most powerful language model. It now involves deciding how knowledge should be stored, retrieved, processed, verified, and presented to users.
Developers who understand both Retrieval-Augmented Generation and long-context architectures will have a significant advantage. Instead of treating them as competing approaches, they’ll be able to choose the most suitable solution based on each project’s requirements. A chatbot answering customer queries may benefit from RAG, while a legal document analysis platform may perform better with a long-context model capable of reviewing hundreds of pages simultaneously.
This shift also changes the skills developers need. Knowledge of vector databases, embeddings, prompt engineering, document chunking, context management, reasoning strategies, and AI evaluation will become increasingly valuable as organisations adopt more sophisticated AI systems.
Perhaps most importantly, developers will need to think beyond simply generating answers. The future of AI is moving towards reasoning, decision support, workflow automation, and intelligent agents capable of solving multi-step problems rather than responding to isolated prompts.
Common Misconceptions About the ‘Death of RAG’
The popularity of the phrase “RAG is dead” has led to several misunderstandings within the AI community. While the discussion has helped draw attention to long-context models, it has also created unrealistic expectations about what these systems can achieve on their own.
Some of the most common misconceptions include:
- Long-context models eliminate the need for retrieval. In reality, retrieval remains essential for accessing continuously updated information, especially in enterprise environments where new documents are created every day.
- A larger context window automatically produces better answers. While additional context can improve reasoning, irrelevant or poorly organised information may actually reduce response quality. Selecting the right information is often just as important as providing more information.
- All businesses should immediately replace RAG with long-context models. Every organisation has different requirements. The best architecture depends on document volume, update frequency, operational costs, compliance requirements, and user expectations.
- Vector databases are becoming obsolete. Vector search continues to play a crucial role in semantic retrieval, recommendation systems, enterprise search, and AI applications that require fast access to relevant knowledge.
Recognising these misconceptions helps businesses make technology decisions based on practical needs rather than industry hype.

The Bigger Picture: AI Is Moving from Search to Understanding
One of the most fascinating developments in recent years is that AI is gradually shifting from retrieving information to understanding it. Traditional search engines helped users find documents. Modern AI systems increasingly help users interpret those documents, identify relationships, generate insights, and recommend actions.
This evolution explains why the debate surrounding Google Gemini and Retrieval-Augmented Generation has attracted so much attention. The discussion isn’t simply about memory size or token limits. It’s about how people will interact with knowledge in the future.
Imagine asking an AI not just to locate a financial report, but to explain why profits declined over three years, compare that trend with competitor performance, identify operational risks, and suggest strategic improvements. That type of reasoning requires more than search—it requires context, analysis, and understanding.
As language models continue to improve, users will increasingly expect AI to function less like a search engine and more like an experienced analyst capable of connecting ideas across vast amounts of information.
Final Thoughts: RAG Isn’t Dying—It’s Evolving
The debate surrounding Retrieval-Augmented Generation and Gemini AI’s 2 Million Token Context reflects how quickly the field of artificial intelligence is advancing. Only a short time ago, RAG was considered the definitive solution for improving the accuracy of Large Language Models. Today, long-context architectures are expanding what’s possible by enabling AI to analyse much larger collections of information within a single interaction.
However, declaring the “death” of RAG overlooks the broader picture. Retrieval systems continue to solve challenges that long-context models alone cannot address efficiently, particularly when dealing with dynamic knowledge bases, continuously updated information, and enterprise-scale repositories. At the same time, long-context models unlock entirely new forms of reasoning that were previously difficult or impossible using traditional retrieval pipelines.
Rather than replacing one another, these technologies are increasingly becoming complementary components of modern AI architectures. The most capable systems of the future are likely to retrieve the right information, analyse it using massive context windows, reason across multiple sources, verify their conclusions, and deliver responses that are both accurate and transparent.
For businesses, developers, researchers, and everyday users, the message is clear. The future of Enterprise AI isn’t about choosing between Retrieval-Augmented Generation and long-context models. It’s about understanding when to use each approach and how to combine them effectively.
The next chapter of AI won’t be defined by the death of RAG.
It will be defined by the intelligent partnership between retrieval, reasoning, memory, and ever-expanding context windows.
Frequently Asked Questions (FAQs)
What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI architecture that allows a language model to retrieve relevant information from external documents, databases, or knowledge repositories before generating a response. This helps improve accuracy, reduce hallucinations, and provide answers based on current information rather than relying only on the model’s training data.
Does Gemini’s 2 Million Token Context replace RAG?
Not completely. Google Gemini’s large context window allows it to process significantly more information in one prompt, making certain tasks easier. However, Retrieval-Augmented Generation remains valuable for accessing frequently updated information, managing very large knowledge bases, and reducing computational costs in enterprise environments.
What is a context window in AI?
A context window refers to the amount of text an AI model can process during a single interaction. A larger context window enables the model to analyse longer documents, connect ideas across multiple sources, and generate more coherent responses based on a broader range of information.
Why are long-context models important for data analysis?
Long-context models improve AI Data Analysis by allowing large collections of documents to be analysed together rather than individually. This helps identify patterns, relationships, inconsistencies, and trends that may not be visible when documents are processed separately.
Will businesses stop using RAG in the future?
Most experts believe businesses will continue using Retrieval-Augmented Generation, especially for applications involving continuously changing information and enterprise knowledge management. Instead of disappearing, RAG is expected to work alongside long-context models as part of hybrid AI architectures.